k8s.gcr.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2 被墙无法pull,使用nfs方式提供k8s PVC必须的镜像包。 本人小水管拉下来的,拿走不谢。 使用方法: #解压 tar -xvf k8s.gcr.io_sig-storage_nfs-...
”kubernetes oci hacktoberfest runc container-runtime-interface oci-runtime kata-containers k8s-sig-node Hacktoberfest“ 的搜索结果
先举个例子,分别以不指定编码、指定编码为 utf-8、指定编码为 utf-8-sig 三种方式来做比较,再将写入 csv 文件和 txt 文件来做个对比 一、不指定编码方式,直接存入 csv 文件 import csv with open('test.csv', '...
As UTF-8 is an 8-bit encoding no BOM is required and anyU+FEFF character in the decoded Unicode string (even if it’s the firstcharacter) is treated as a ZERO WIDTH NO-BREAK SPACE. ...
转:... As UTF-8 is an 8-bit encoding no BOM is required and anyU+FEFF character in the decoded Unicode string (even if it’s the firstcharacter)...
二、python脚本,读取txt文件时,encoding="utf-8-sig" file_path = "E:/国际化/" with open(file_path + "English.txt", encoding="utf-8-sig") as obj_file: english_content = obj_file.read() 三、将BOM头...
json文件读取成dataframe出现了yurf-8编码错误
松弛通道:#SIG-APP-交付CNCF工作空间- 邮件列表: : 会面 我们每个月的第1个和第3个星期三,太平洋标准时间上午8:00开会。 议程和注释: : 变焦会议: ://zoom.us/j/7276783015 Passcode = 77777 先前会议...
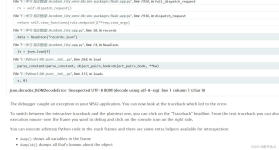
json.decoder.JSONDecodeError: Unexpected UTF-8 BOM (decode using utf-8-sig): line 1 column 1 (char 0) 这个报错的原因是用json.loads()将文本转换成json时,文本首部出现了BOM。 用以下两行代码可以去掉。 ...
nfs-subdir-external-provisioner unexpected error getting claim reference: selfLink was empty, can't make reference elfLink was empty

最近在读取jason文件时报错,原因是因为文件包含BOM字符,去掉BOM字符, 在content = f.read()代码下加上: if content.startswith(u'\ufeff'): content = content.encode('utf8')[3:].decode('utf8') ...
零. 概述 主要介绍下蓝牙协议栈(bluetooth stack) 电话免提协议HFP(Hands-Free) 协议概念介绍。 一.... 本专栏文章我们会以连载的方式持续更新,本专栏计划更新内容如下: ...第一篇:蓝牙综合介绍 ,主要介绍蓝牙的...

Kubectl --v操作演示 [root@10 ~]# kubectl get pod --v=0 NAME READY STATUS RESTARTS AGE api-demo-56db594ddf-rc5jf 1/1 Runni...
今天,在使用sudo yarn install拉取依赖包时,报"无法访问 'https://github.com/ethereumjs/ethereumjs-abi.git/'"问题,如图(1)所示。出现这种情况的原因:yarn.lock文件里的dependencies字段的ethereumjs-abi 没有...
As UTF-8 is an 8-bit encoding no BOM is required and anyU+FEFF character in the decoded Unicode string (even if it’s the firstcharacter) is treated as a ZERO WIDTH NO-BREAK SPACE. ...
在2021年, OpenHarmony Dev-Board-SIG频繁爆出新进展,是OpenHarmony项目组群中最活跃的SIG之一,我们邀请到了OpenHarmony Dev-Board-SIG负责人 刘洋,深入了解Dev-Board-SIG在开源运作中的策略以及2022年的规划。...

python使用UTF-8写入CSV中文乱码 使用encoding=‘utf-8’,写入的文档是乱码: def save_contents(urlist): with open("filename"+".csv","a+",newline='', encoding='utf-8') as f: writer = csv.writer(f) ...




r =requests.post(page_url,headers=headers,data=data_info) ...decoded_data=codecs.decode(r.text.encode(), 'utf-8-sig') data = json.loads(decoded_data) 解决方案2-不使用编解码器模块...

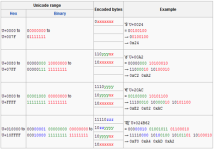
先看图 : 但内容都一样 ,为什么相差了3个字节呢 ? 如下图 。 多出来的 ef bb bf 就是上面相差三个字节的原因 。 为什么 with bom 要多着三个字节呢 ?...BOM——Byte Order Mark,就是字节序标记 ...
前言:在写入csv文件中,出现了乱码的问题。 解决:utf-8 改为utf-8-sig 区别如下: 1、”utf-8“ 是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节...2、“uft-8-sig"中sig全拼为 signature 也就是...
notepad++打开文件 -> 格式 ->以utf-8无bom模式编码 ->保存
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地